
One of the most sought-after skills in the field of AI is Deep Learning. A Deep Learning course teaches the foundations of Deep Learning and makes one capable of building neural networks and driving Machine Learning projects with success.
It includes case studies from real-life situations such as autonomous driving and natural language processing.
As a result, the course helps one not just grasp the theory but also apply it to industry use. But, is it enough to start with a deep learning course right away?
We’ll discuss, not just the popularity of Deep Learning in recent years, but also what Deep Learning and neural networks are. So, let’s get started.
The popularity of Deep Learning
The entire hullabaloo around AI boils down to two core concepts – Machine Learning and Deep Learning. Machine Learning is a way to create smart machines where algorithms sift through data, learn from them, and apply it to make intelligent decisions.
But, what is Deep Learning? It is a facet of Machine Learning but more ‘human-like’ compared to Machine Learning. That’s because Deep Learning performs the same task of sorting through data, but does so in a manner that mimics the human brain’s neural network.
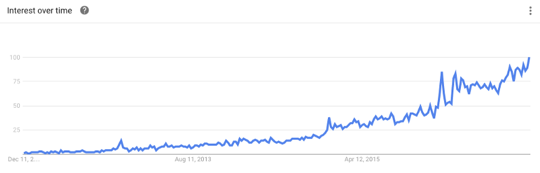
Google trend for the ‘Deep Learning’ keyword
The onslaught of AI-powered services and products results from advancements in algorithms and techniques developed by Deep Learning architects over the last decade. The journey of Deep Learning began in 2009 with the creation of ImageNet and the subsequent development of computer vision algorithms.
In 2014 came GAN, a Deep Learning artificial neural network. In the next few years, AI saw a meteoric rise to achieve superhuman abilities. Boston Dynamics came up with autonomous robots, Skydio developed the first automatic navigation drones, and the day seems not far when driverless cars will make it to the road. Also, Deep Learning is at the core of researchers’ current efforts to produce human-level AI.
All in all, this is just the beginning of the Deep Learning era, and it’s here to stay.
Deep Learning and types of Neural Networks
Deep Learning uses neural networks to manipulate and process data. Primarily, a neural network consists of neurons that are interconnected through weights (the lines in the image). Numerical inputs are fed to the neurons and multiplied by the weights.
By changing the weights’ numerical values, the neural network can be used to process data to get the desired output.

Here are the most notable types of neural networks:
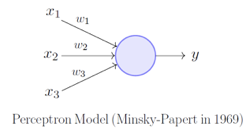
- Perceptron: Created in 1958, Perceptron is the oldest and most straightforward neural network. It consists of only one neuron. It can be fed with an ‘n’ amount of inputs, which gets multiplied by the corresponding weights to generate one output.
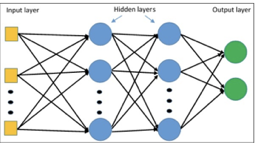
- Multi-layer Perceptron: It consists of three layers. The input layer accepts numeric input data, the hidden layer has neurons to manipulate the data, and the output layer gives the result of data manipulation.
- Autoencoders: These neural networks compress data without disturbing the quality. The hidden layer is smaller than the other two layers and is known as the “bottleneck”. The reduced size forces the hidden layer to compress the input data and then put it in the output layer.
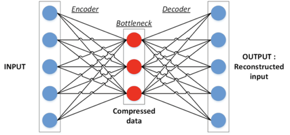
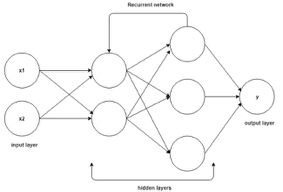
- Recurrent Neural Network (RNN): RNNs can analyze temporal data that predicts the future using past instances. RNNs store the last output in their memory, called ‘state matrices’. The state matrix, in turn, is used to calculate the new output. RNNs are useful in stock market predictions and time-based prediction of data.
What is CNN and where is it used?
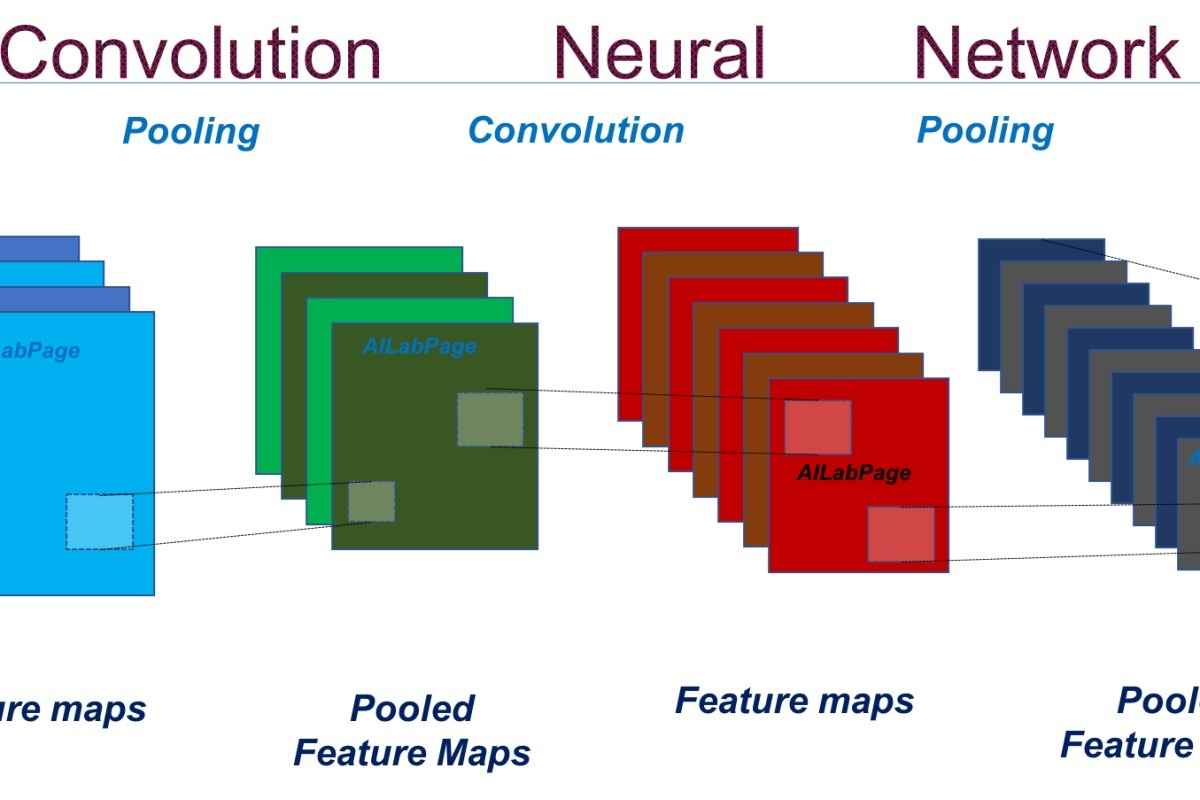
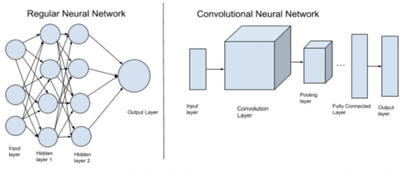
Convolutional Neural Network is a type of feed-forward neural network. It is quite similar in principle to the multi-layer Perceptron but incorporates the use of convolutional layers. CNN is based on a hierarchical model that works like a funnel.
It begins with building a network that finally produces a fully-connected layer, comprising all the interconnected neurons and where the output is processed.
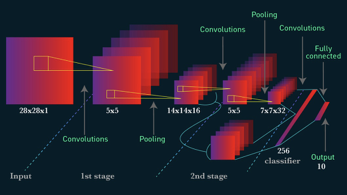
Images comprise a grid of numbers where each number is an indication of the pixel intensity. The numbers in the grid can be manipulated to discover patterns and understand the characteristics of the image. Convolutional layers achieve this by using filters.
A filter is an n x m grid of numbers that gets multiplied with the original input image several times. In CNN, the filter moves across the grid (image) to produce new values. The new values can represent lines or edges in the image. After applying the filters to the entire image, the main features are extracted using a pooling layer.
The pooling layer collects the most significant characteristics found by the filters to give the final result. CNN offers high accuracy and is mostly used for image recognition and classification, computer vision, and finding characteristics or patterns in images.
Conclusion
Big data enterprises have been using AI and Deep Learning for quite a while now. But, the general public has been most fascinated by how Alexa and Google Assistant’s disembodied voices are so efficient in helping them or maybe how Spotify correctly guesses what we’d like to hear. All of this couldn’t have been possible without Machines and Deep Learning.
The next decade may see the arrival of cutting-edge algorithms, but we can vouch for the fact that we’d still be relying on Deep Learning. So, could there be any better time to sign-up for a Deep Learning course?





{kind=link}